Side Eye: Acoustic Eavesdropping from Smartphone Cameras

Overview:
Side Eye is a vulnerability in smartphone camera hardware that allows adversaries to extract acoustic information from a stream of camera photos.
When sound energy vibrates the smartphone body, it shakes camera lenses and creates tiny Point-of-View (POV) variations in the camera images.
Adversaries can thus infer the sound information by analyzing the image POV variations.
Side Eye enables a family of sensor-based side channel attacks targeting acoustic eavesdropping even when smartphone microphone is disabled,
and does not require specific objects within the camera's field of view.
Side Eye is to appear at IEEE Symposium on Security and Privacy 2023
Code and replication: Side Eye is a patent-pending technology so we are unable to share the detailed system implementation now. If you have questions regarding how to implement it, feel free to contact Yan Long. In addition, we provide the Android app for video recording.
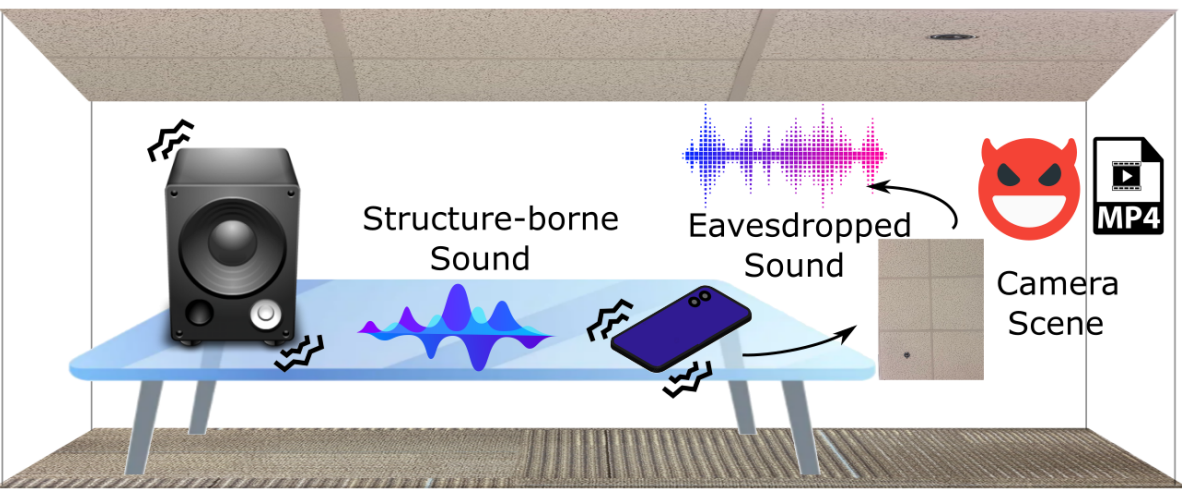
Some examples of the original and side channel-recovered audio signals are provided below.
The original audio is from the AudioMNIST dataset.
The recovered signals are extracted from image streams recorded by the rear camera of a Google Pixel 3 smartphone when
an electronic speaker is playing the original audio at 85 dB.
Although the recovered audio does not allow listeners to directly tell what exact words are spoken without any reference,
it preserves clear low-frequency tones that allow listeners to tell the gender and even identity of the speaker.
Listeners may also be able to differentiate between different words and sentences when given a closed set of possible candidates.
Side Eye further provides a deep learning model that can recognize individual
words with high accuracies.
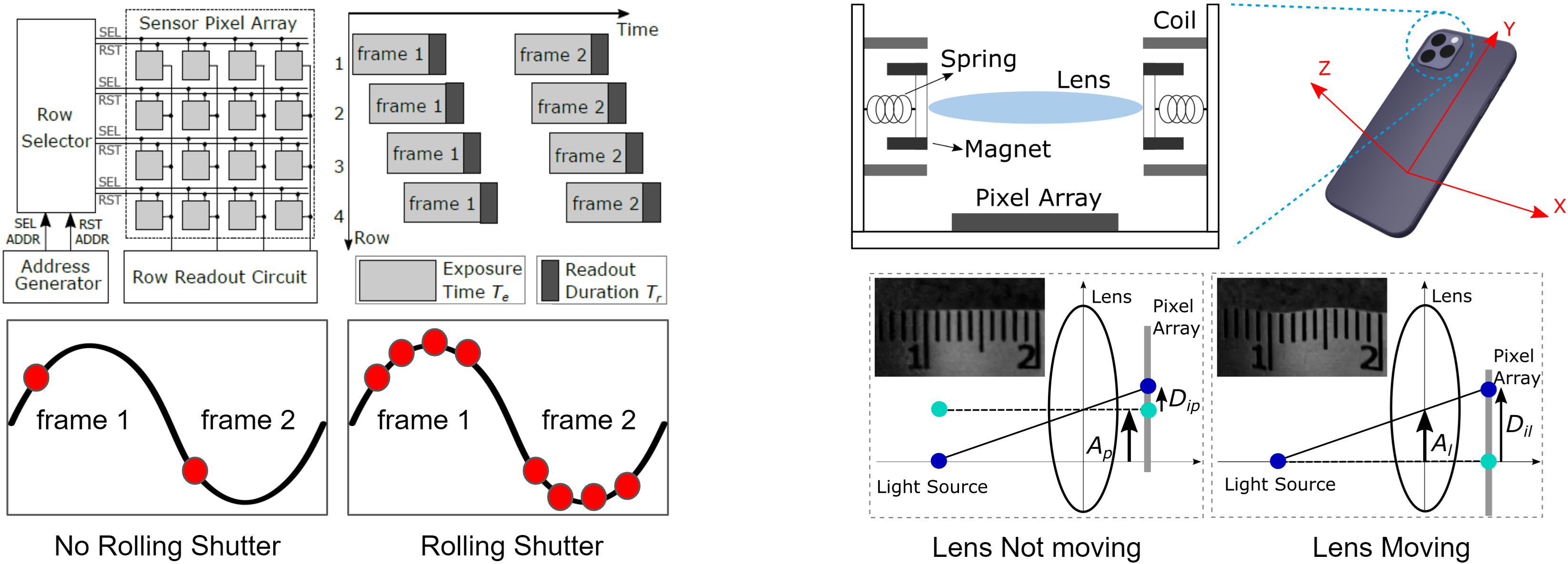
Side Eye extracts the POV variations in image streams using a diffusion image registration-based algorithm.
The extraction algorithm exploits the rolling shutter feature of smartphone cameras to
increase the effective sample rates of recoverable acoustic signals from the image stream frame rate (~30Hz)
to the camera's rolling shutter frequency (over 30k Hz).
The extracted raw signals are further cleaned up by a pre-processing pipeline, whose output are demonstrated by the audio samples.
Side Eye provides a HuBERT-based deep learning model that can recognize the gender (2-class), identity (20-class),
and speaker independent spoken digits (10-class) with up to 99.67%, 91.28%, and 80.66% accuracies.
Our evaluations show that the signal processing and deep learning pipeline allow adversaries to extract non-trivial acoustic information in various scenarios, including: (1) the speaker and phone are left on different desks;
(2) the speaker is left on the floor and the phone is in the pocket of a shirt or a backpack worn by a mannequin;
(3) the speaker and phone are placed in two different rooms.


The culprits of Side Eye attacks are the rolling shutter architectures and moveable lens structures found in most smartphone cameras.
Rolling shutters expose each row of the camera image sensor sequentially. This increases the number of sampling points that adversaries have access to when performing computations on the image streams, increasing the amount of acoustic information leaked into images. Without exploiting rolling shutters, the sample rate of the acoustic signals that the adversaries can recover is the same as the frame rate of the image streams (often 30 Hz). By understanding and exploiting rolling shutters, the adversaries can increase the sample rate to the same as the rolling shutter frequency, i.e., the row-wise sequential scanning frequency (often over 30k Hz).
Moveable lenses amplify the camera's optical path variations when the phones are vibrated by sound energy. There exists relative movements between the camera lens and smartphone body when the smartphone body moves under sound waves. This increases the amplitude of the sound-induced POV variations in the images, leading to significantly higher signal-to-noise ratios for the adversaries. These moveable lens structures are employed by camera manufacturers for auto-focusing (AF) and optical image stabilization (OIS) functions.
The camera senses nearby sounds without actually aiming at any objects generating or being vibrated by the sound waves because the sound waves vibrate the camera lens itself and cause point-of-view variations. We call this attack Side Eye because the camera is "seeing" something aside that is out of its field-of-view.
Almost all modern smartphone cameras since rolling shutters and moveable lenses are ubiquitous nowadays. The rear (main) cameras are often more susceptible because their lenses can move more under ambient sound waves. In our research paper, we demonstrated case studies on 10 smartphone models from Samsung, Google, and Apple.
Side Eye attacks can happen if adversaries get access to a burst of camera photos (in another word, a muted video) from your smartphone when the smartphone camera recorded the photos near an electronic speaker playing audio. Such electronic speakers can be standalone loudspeakers in the room or even the internal speakers of your TVs, laptops, and smartphones. The adversaries can be either passive eavesdroppers to whom you share your photos without knowing the photos could contain audio information, or active attackers taking the form of smartphone applications that are granted permissions to use smartphone cameras.
Almost all types of audio information (e.g., speech, music, etc.) from electronic speakers can be leaked with present-day smartphone cameras. Louder audio can be leaked more easily because it can induce larger POV variations in images. That said, we found audio played at normal and quiet conversation volumes (65 and 55 dB SPL) can also leak a significant amount of information when the acoustic signals are extracted and recognized by our signal processing and deep learning pipeline.
It is worth noting that our evaluations show Side Eye cannot be used to eavesdrop on audio from human speakers with present-day smartphone cameras yet because sound waves generated by human speakers cannot vibrate the lenses enough to generated distinguishable POV variations. Nevertheless, future cameras with higher pixel resolution and lower imaging noises might be able to capture human speech signals.
For smartphone users, the first thing is to realize that cameras can also leak audio. So when granting camera access to applications, keep in mind you could also be sharing some audio information to the applications even if you do not give them microphone access. Furthermore, you may want to be cautious when sharing muted videos to others, especially if they were taken near electronic speakers. You may also consider putting your cameras away from electronic speakers in the room to reduce the amount of audio leaked into camera images. A useful tip for assessing if there is a risk of Side Eye attack is to put your hand on your smartphone and feel if there is sound-induced vibrations. If your hand feel vibrations caused by nearby electronic speakers, then there is a high risk your camera can also capture it.
Our research paper discussed in detail the possible hardware fixes that camera manufacturers may consider, including those aiming to address the rolling shutter problem and those aiming to address the movable lens problem respectively. We found preventing camera lenses from moving when it is not supposed to (i.e., when there is ambient sounds) is the most effective solution. From the user standpoint, this can be achieved by placing external magnets by the smartphone cameras to fix the position of the internal lenses whose supporting structures are also magnet-based. This is similar to how people tried to use magnets to fix their shaking camera problems. However, this temporary fix carried out by users may damage the cameras' internal mechanical and electrical structures.
It is also worth pointing out that we haven't found any effective software fixes to this problem since the root cause is hardware-based. Software approaches such as using lower resolution images will greatly affect usability while only providing very limited decrease in the acoustic information captured by cameras.
The techniques used by Side Eye provides a mechanism for extracting other vibrational modalities of signals (e.g., acceleration and angular velocity) from images, potentially reducing the number of sensors needed. Besides adversarial applications, it may also be used by system defenders. Our workshop paper Side Auth provides some insights and examples.
Unfortunately, it cannot. With a global shutter, the number of sampling points decreases by 1080x with 1080p-resolution images. But Side Eye's deep learning model is still able to exploit the few sampling points (with a sample rate same as the frame rate) to recover non-trivial information. For example, we found out the accuracies of recognizing 10-class spoken digits drop from ~80% to ~40% when the rolling shutter is replaced with a global shutter. Although rolling shutters capture additional inner-frame information, global shutters still capture inter-frame information.
First, smartphone motion sensors measure smartphone vibrations caused by sound energy directly. Side Eye decodes such signals from videos based on understandings of how sound waves are modulated onto POV variations of camera images.
Second, most smartphone motion sensors have maximum sample rate of about 500 Hz, allowing adversaries to infer acoustic signals with a bandwidth of up to 250 Hz. Side Eye exploits the rolling shutter features of cameras and support over 30k Hz sample rate. We observe a signal bandwidth of up to 600 Hz so far.
Third, motion sensor data is rarely shared over internet. Side Eye studies another medium of information: camera images/muted videos, which are often shared by users themselves at will to others. This creates an orthogonal space of possible information leakage scenarios.
Previous research of using cameras to measure audio signals requires aiming specialized high-quality cameras at objects that are either generating sounds (e.g., loudspeakers and humans) or vibrated by sound (e.g., lightweight chip bags). In short, they require specific objects in the camera field-of-view. Side Eye exploits the point-of-view variations caused by smartphone camera intrinsic physics. Furthermore, Side Eye provide signal extraction algorithms that are optimized for extracting POV variations and a state-of-the-art deep learning model for recognizing the extracted signals which are difficult for humans to understand directly.
No, we were able to obtain the best results with the HuBERT classifier model, but we had relatively similar success with much smaller models, such as ResNET-50 using spectrograms as inputs. When using different models for classification, improved performance is obtained when the model has been pre-trained on other and perhaps unrelated datasets such as ImageNet. Also, our experiments with different models indicate that using 8 extracted channels from the optical-acoustic side-channel outperforms using only one channel. As a result, the classification model may need to be modified to accept additional input channels.